

Blog
SEO
18.09.2025
Unsere aktuelle Studie zeigt: KI-Crawler wie ChatGPT und Gemini lesen keine strukturierten Daten, sondern nur sichtbaren Text. Wer in AI-Channels präsent sein will, muss umdenken – und seine Seitenarchitektur anpassen.
Von Julio C. Guevara & Sten Rakotomalala
Mit dem Aufstieg von KI-Suchsystemen wie ChatGPT oder Gemini stellt sich für viele Marken die Frage: Wie bleiben wir sichtbar, wenn klassische SEO-Mechanismen nicht mehr greifen?
Eine Empfehlung, die aktuell über mehrere Kreisen wiederholt wird, von zahlreichen Toolanbietern und Agenturen, ist die Verwendung von strukturierten Daten (JSON-LD) als „AI-Kontext-Booster“, der angeblich die Sichtbarkeit in Chatbot-Antworten erhöht. Doch bislang fehlten Belege dafür, dass dies tatsächlich funktioniert.
Unser aktueller Test zeigt ein anderes Bild: AI-Crawler arbeiten fast ausschließlich mit sichtbarem Text, nicht mit Code- oder Metadatenstrukturen.

Woher wir das wissen? Wir haben’s ausprobiert.
Ziel dieser Studie war es nicht, die Anzahl der Erwähnungen zu messen, sondern herauszufinden, aus welchen Seitenelementen AI-Channels ihre Informationen beziehen.
Dazu wollten wir testen, ob ein LLM in der Lage ist, Informationen direkt aus JSON- oder Schema-Daten zu extrahieren und in seinen Antworten zu verwenden („Hypothese: strukturierte Daten führen direkt zu AI-Erwähnungen“).
Eine zentrale Herausforderung bestand darin, sicherzustellen, dass keine externen oder sichtbaren Quellen die Ergebnisse verfälschen. Wenn dieselben Informationen beispielsweise auch im HTML-Text stehen oder bereits über andere Kanäle wie Presse, Social Media oder öffentliche Datenbanken bekannt sind, könnten die Modelle sie schon aus Training oder RAG-Daten kennen.
Um das auszuschließen, haben wir ein vollständig isoliertes Testumfeld geschaffen mit einem fiktiven Produkt und ohne externe Referenzen.
Im ersten Testdurchlauf führten wir insgesamt 160 Abfragen (n = 160) zu unterschiedlichen Schema-Typen durch – darunter Product, BlogPosting, Review und Organization. Ziel war zu prüfen, ob ein LLM Inhalte aus diesen strukturierten Daten direkt ausliest und in seine Antworten integriert.
Wir führten einen A/B-Test mit mehreren Seitentypen und unterschiedlichen strukturierten Daten durch, um dies verifizieren zu können:

Consultant SEO
Das Ergebnis des A/B-Tests war eindeutig: Keines der getesteten Schema-Formate wurde von den AI-Systemen erkannt oder genutzt, alle Antworten basierten ausschließlich auf sichtbarem HTML-Text.
Bei der Extraktion von Informationen (z.B. Preis, Produkt Namen, Varianten, Organisations Adresse, etc.) aus Seiten, die ausschließlich deren Infos in JSON Format hatten, konnten KI-Kanäle keine Antwort geben. Sobald jedoch sichtbarer Content in HTML (also normaler Textform) vorhanden war, konnten ChatGPT und Gemini die Informationen problemlos erkennen und in Antworten verarbeiten.

Nicht einmal wurden die Inhalte aus der JSON Gruppe richtig extrahiert, egal wie präzise und explizit diese aus der URL abgefragt worden sind. Damit wird klar: Für KI-Antworten zählt nicht nur der Code, sondern der Inhalt, der auf der Seite sichtbar gerendert wird.
Man würde denken, dass Seiten, wo die wichtigsten Infos nur über JSON weitergegeben werden, selten in der Praxis zu finden sind. Warum sollten wir uns darum kümmern?
Erstens: Viele Webshops mit dynamischem Content bestehen heute aus sehr wenig HTML – der Großteil der Produktinformationen wird clientseitig über JSON ausgeliefert. Das ist technisch effizient, stellt jedoch ein Problem für AI-Crawler dar, die nur sichtbaren Text indexieren.
Zweitens: Das zeigt uns auch, dass die Korrelationseffekte, die man bei KI-Mention Anstiege nach der Anführung von Structure Data manchmal sieht, auf Ranking-Systeme zurückzuführen sind (SEO) und nicht auf „den Kontext-Boost für Maschinen” über strukturierte Daten.
LLMs funktionieren fundamental anders.
Diese Beobachtung deckt sich auch mit einer Analyse von Mark Williams-Cook, der erklärt, warum LLMs Schema-Daten gar nicht effektiv verarbeiten können. Beim sogenannten Tokenizing zerlegen Sprachmodelle den Text in kleinste Zeichenfolgen („Tokens“). Dabei werden Strukturinformationen (etwa aus JSON-LD) zerstückelt und verlieren ihre Bedeutung.

Um diesen Effekt zu prüfen, haben wir einen zweiten Test durchgeführt. Dafür haben wir zwei Seiten genommen, die dasselbe Produkt anbieten, jedoch auf unterschiedlichen Tech-Stacks basieren:
Um die Praxistauglichkeit zu prüfen, testeten wir 70 konkrete Produktabfragen an ChatGPT 4o/o3 und Gemini 2.5 Flash/Pro. Das Ergebnis bestätigte unsere Hypothese: Nur die HTML-basierte Seite wurde von den AI-Systemen vollständig erkannt und in Antworten berücksichtigt – die JSON-basierte Seite blieb für ChatGPT und Gemini praktisch unsichtbar:
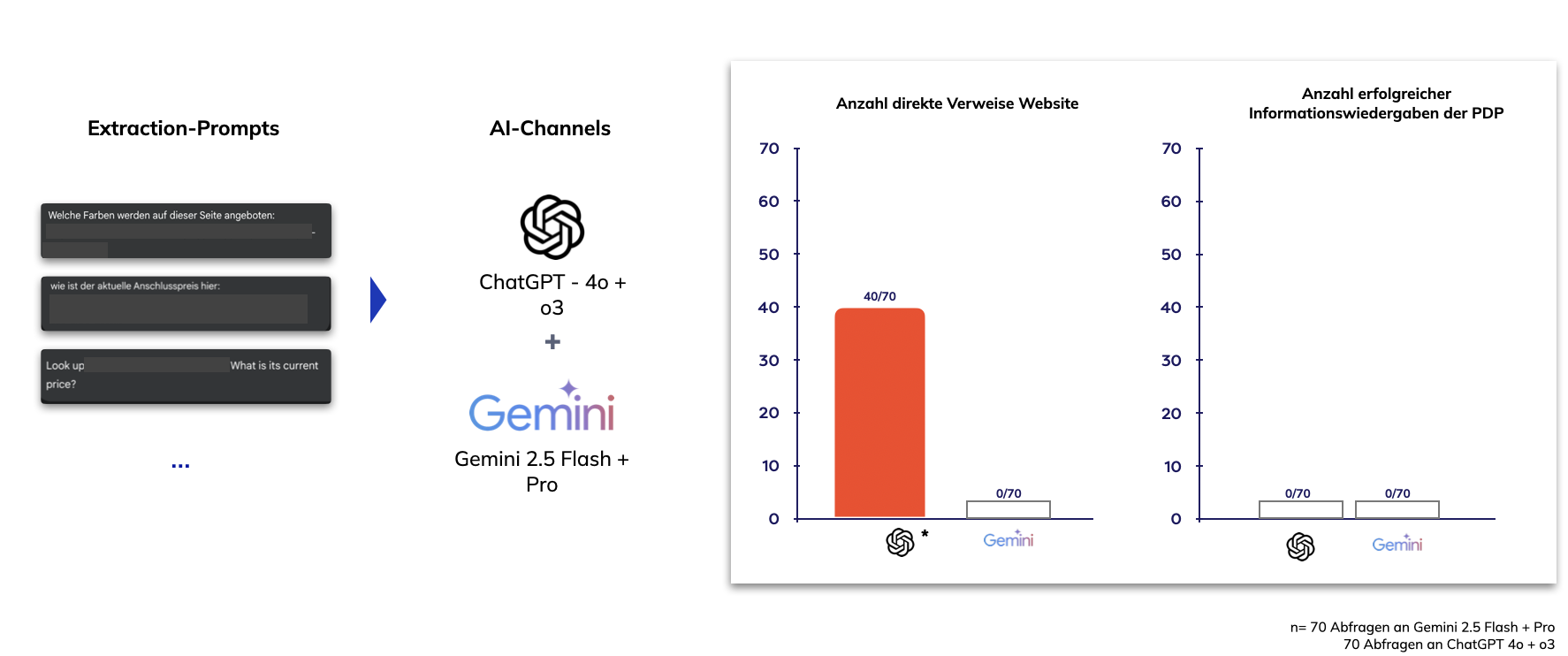
Für die aktuelle Generation von KI-Systemen spielt sichtbarer, textbasierter Content die entscheidende Rolle. Strukturierte Daten allein reichen nicht aus, um in LLM-Antworten aufzutauchen. AI-Channels interpretieren Inhalte unterschiedlich und reagieren sensibel auf fehlende Datenstrukturen.
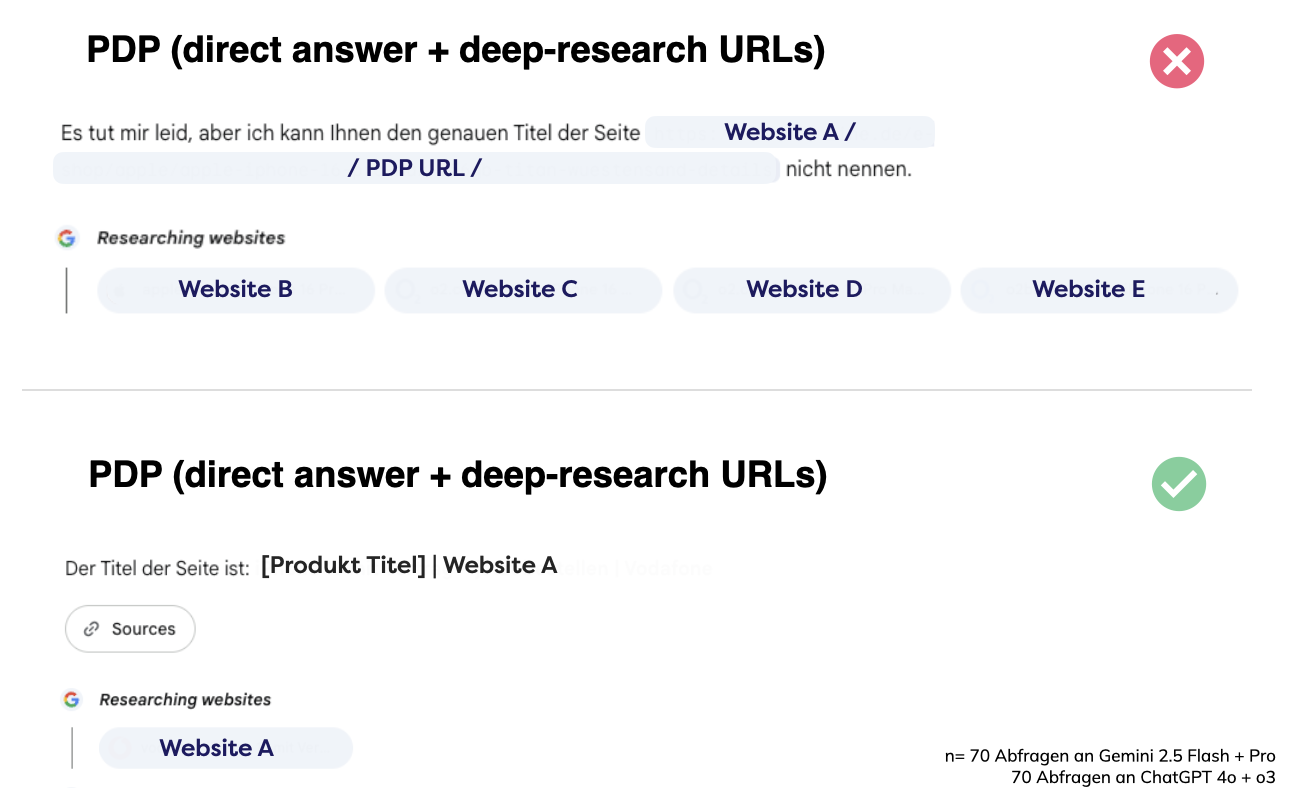
Während ChatGPT versucht, Lücken zu schließen, riskiert es dabei Fehldarstellungen indem es auf fremde Quellen zurückgriff oder halluziniert. Gemini dagegen erkennt, wenn Informationen nicht verfügbar sind, und kommuniziert dies transparent, anstatt ungenaue Antworten zu generieren.
Beides ist problematisch: entweder Fehlinformation oder Sichtbarkeitsverlust.
Marken verlieren damit entweder die Kontrolle über ihre Botschaft oder verschwinden ganz aus dem AI-Kontext. Nur sichtbarer, serverseitig gerenderter Content kann dieses Risiko zuverlässig vermeiden.
Warum ist das so eigentlich?
Große Sprachmodelle wie ChatGPT sind darauf trainiert, immer eine Antwort zu geben, selbst dann, wenn keine korrekten Informationen vorliegen. Das liegt unter anderem an der Art, wie ihre Leistung bewertet wird: In aktuellen Evaluationsverfahren zählt vor allem, wie oft ein Modell eine „richtige“ Antwort liefert. Diese Metrik fördert ein Verhalten, das eher zum Raten als zum Eingestehen von Unsicherheit anregt.
Man kann es sich wie bei einem Multiple-Choice-Test vorstellen: Wer rät, hat zumindest eine Chance auf Punkte; wer die Frage offen lässt, bekommt sicher null. Genau dieses Prinzip sorgt dafür, dass Modelle lieber versuchen, eine plausible Antwort zu formulieren, statt offen ein „Ich weiß es nicht“ zu geben.
Aus den Ergebnissen lassen sich drei klare Prinzipien ableiten, die künftig über Sichtbarkeit in KI-Kanälen entscheiden:
AI-Visibility ist also kein technischer Zufall, sondern das Ergebnis sauberer Tech-Stacks.

Unsere Tests zeigen eindrucksvoll, dass strukturierte Daten allein nicht genügen. Wer in KI-Kanälen wie ChatGPT oder Gemini präsent sein will, muss sicherstellen, dass seine Inhalte klar lesbar, textbasiert und serverseitig gerendert sind.
Dynamische oder ausschließlich clientseitige Strukturen bergen das Risiko, dass Inhalte gar nicht erkannt werden – oder von fremden Quellen ersetzt werden.
Für Unternehmen heißt das konkret:
Die Zukunft der Online-Sichtbarkeit entscheidet sich nicht mehr nur in Suchmaschinen – sondern zunehmend in AI-Systemen. Wer frühzeitig versteht, wie diese Inhalte wirklich „sehen“, gewinnt einen entscheidenden Vorsprung.
Quelle:
OpenAI. (2025). Why language models hallucinate. Abgerufen am 08.10.2025, von https://openai.com/index/why-language-models-hallucinate/
Mark Williams-Cook. (2025). Unsolicited #SEO tip: visual explanation why LLMs do not use schema in training data [LinkedIn-Beitrag]. Abgerufen am 08.10.2025, von https://www.linkedin.com/posts/markseo_seo-activity-7363511170965630984-OZtu/




Hamburg
Gorch-Fock-Wall 1a
20354 Hamburg
T: +49 (0) 40 411 255 68 - 0
F: +49 (0) 40 411 255 68 - 8
E-Mail: info@img.ag
Standorte der Relevance Group unter anderem in...
... Berlin
... Düsseldorf
... Zürich
... Amsterdam
... Brüssel
... und viele mehr ...





